Reflection on Building Swiss AI Serving
Over the past year, I had the privilege to build an internal system (SwissAI Serving) at Swiss AI Initiative for accessing large-scale ML models, on top of a toy project I built several years ago. SwissAI Serving is a system designed to overcome the challenges faced by universities and research institutes in accessing large-scale machine learning (ML) models. Over the past year, the system has processed 16 million requests and 14 billion tokens. We allow all students, researchers, engineers from ETHZ, EPFL, UZH, ZHAW, UNIL and a few other universities or research institutes, together with partners from Swisscom, Federal Tribunal, some other companies, etc to access over 60 LLMs or multi-modality models, without rate limit and free of charge.
Seeing my toy project scale (not so decently though) to a relatively large set of GPUs (which consists of ~100 A100s, a few GH200, and some other consumer-grade GPUs) and millions of requests, is a lot of fun (and blood and tears)!
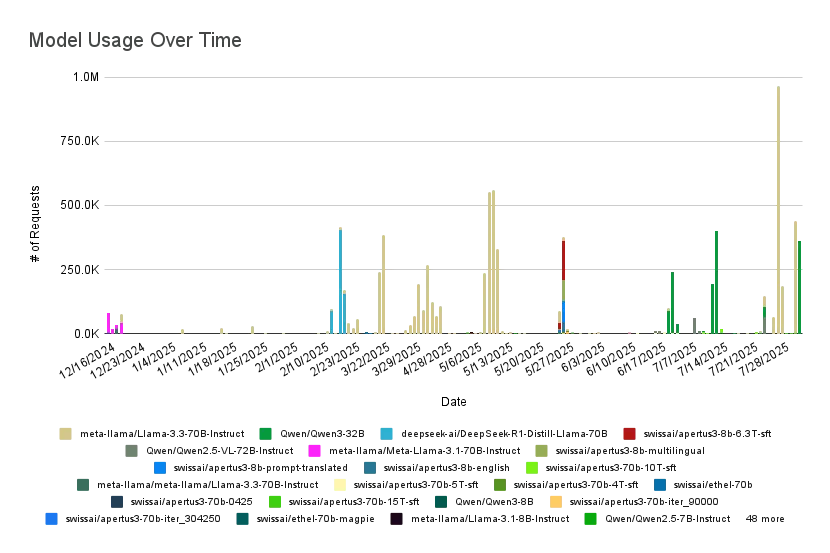 Figure 1: Daily Requests of various models on Swiss AI Serving Platform
Figure 1: Daily Requests of various models on Swiss AI Serving Platform
In this post, I reflect on why, and what are the main differences with commercial platforms (in both good and bad ways), what I have learnt in the process and what are the things we could have done better.
Challenge
Academic institutions often contend with strict data privacy, the high demand for large-scale model access for research, particularly in data curation, generation, and evaluation. Furthermore, different research teams often need various models, even specialized models. On commercial platforms, accessing to those models at large scale can be expensive, or not possible (e.g., a model trained on private dataset) at all.
It would be ideal if, we could have a shared pool that 1) anyone can share their resources if they are idling. 2) anyone can leverage the shared pool to run some models, and those models become available to everyone in the community.
Opportunity & Motivation
In my experience (with many different data centers, JSC, Lumi, Cineca, OSG, Euler, etc.), we often have varying resource utilization — for various reasons (day and night cycles, conference deadlines, slurm planning stage…). To exemplify that, here is an observation on the average utilization at one example data center: ETH Euler Super Computing Center over a month.
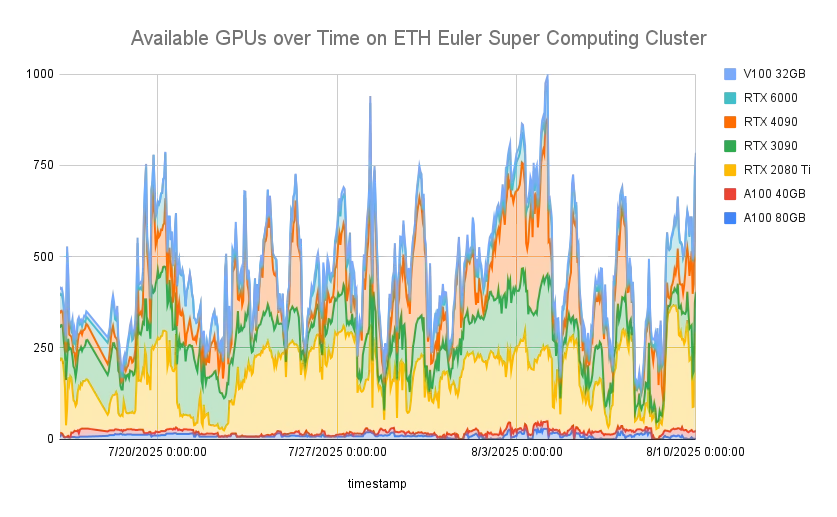 Figure 2: Available GPUs over time on ETH Euler Cluster
Figure 2: Available GPUs over time on ETH Euler Cluster
From the above figure, we found that: 1) even though the overall utilization is high, there are still significant amounts of GPUs idling. 2) The availability of GPUs varies significantly throughout the day. During 3 AM to 7 AM, we observe the highest number of idling GPUs. Conversely, the lowest average GPU availability occurs at around 5 PM, with ~400 GPUs. 3) Different GPUs present different availability, and lower-end, consumer-grade GPUs (RTX 2080Ti, RTX 3090, RTX 4090) exhibit high idling time.
As said, this is not only the case for this particular data center, but also many other data centers that I am aware of. I believe there is a huge opportunity in harnessing those underutilized compute resources, to better accelerate and support AI/ML research.
Design Goals
The system was designed with the goal to harness those under-utilized resources for serving models. Concretely, we have the following goals in mind:
- Flexible and Scalable: Instead of a fixed set of models like many existing commercial platforms, we designed the system to be flexible enough to accommodate a wide variety of ML models and so that we can adapt to evolving research needs.
- Reduce Operational Costs: Unlike commercial platforms, we literally have no budget (except GPU hours). We cannot really hire an OPs team to manage the infrastructure, respond to request to serve a particular model, etc. We hope the system that we build is as self-service as possible, to save money from tax payers.
- Maximize GPU Utilization: There are quite a few different types of GPUs all over several data centers, and we hope our system can efficiently schedule and manages those resources to minimize the idling time and maximize their availability.
To materialize these goals, on a more technical side, we designed the system so that it is:
- Heterogeneous: The system is designed to be heterogeneous, meaning it will leverage a diverse range of GPU specifications. This approach aims to maximize the utilization of existing, often underutilized, compute resources within academic and research institutions, including lower-end consumer-grade GPUs (e.g., RTX 2080Ti, RTX 3090, RTX 4090) which exhibit significant idling time.
- Decentralized: To avoid the complexities and potential bottlenecks of a single point of failure, our system adopts a decentralized architecture. By decentralization, we mean that each single user can spin up an arbitrary number of models through their own account or compute resources, and connect to the shared pool. In this decentralized manner, we avoid the overhead and cost of a centralized administrator who manages the number of resources allocated to each model.
In a very abstract manner, the system is like an exchange or a market, where there are two essential roles:
- Suppliers: who could provide access to a particular model, or a certain type of GPU.
- Users: who access a model through the API or interface.
Implementation-wise, the system is very much like Google docs or spreadsheets: we have a decentralized peer-to-peer CRDT, that will note down what every node is serving. It is dynamic as node might come and go, but it tries it best to provide real-time states of the network.
Interesting Questions & Implementation
We actually came across several interesting questions along the journey.
Placement
The first natural question we came across: which GPUs shall we use? Of course we can use the highest end GPU we can get, but at our scale we will need a lot of high end GPUs if we serve all models with the highest end GPUs. If we were commercial, we would be interested in the cost-efficiency of using particular GPUs instead of the performance-only.
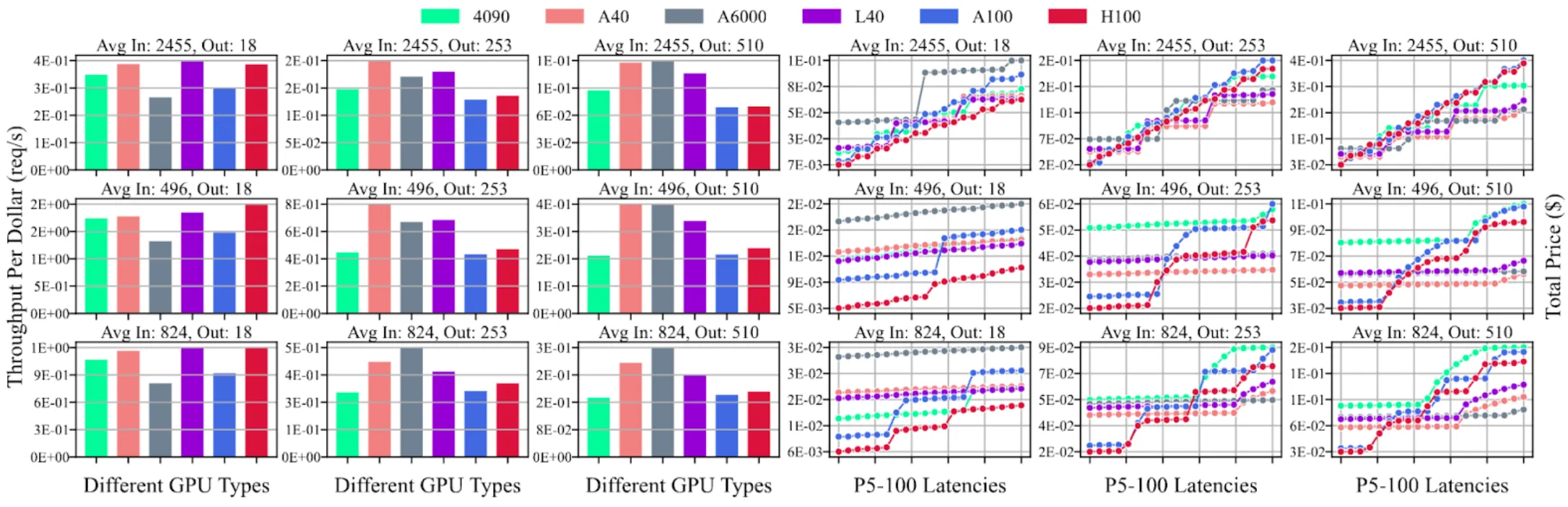 Figure 3: Benchmarked results for Llama3-70B model with different GPU types on different workload types. The left three columns represent the throughput results, x-axis represents different GPU types, y-axis represents throughput per unit price (i.e., throughput divided by GPU cost). The right three columns represent the latency results, x-axis represents the P5-100 latency results (P5-P100 Latencies means from left to right, the x sticks represent P5 Latency, P10 Latency, P15 Latency…), y-axis represents total price (i.e., each latency time multiplied by GPU cost)
Figure 3: Benchmarked results for Llama3-70B model with different GPU types on different workload types. The left three columns represent the throughput results, x-axis represents different GPU types, y-axis represents throughput per unit price (i.e., throughput divided by GPU cost). The right three columns represent the latency results, x-axis represents the P5-100 latency results (P5-P100 Latencies means from left to right, the x sticks represent P5 Latency, P10 Latency, P15 Latency…), y-axis represents total price (i.e., each latency time multiplied by GPU cost)
We benchmarked the performance of various models on various platform, as in Demystifying Cost-Efficiency in LLM Serving over Heterogeneous GPUs, ICML 2025’. Figure 3 highlights the key findings: even if the highest-end GPU yields the best performance, it is often not the most cost-efficient spec. Subsequently, we designed a scheduling algorithm via mixed-integer linear programming, aiming at deducing the most cost-efficient serving plan under the constraints of price budget and real-time GPU availability.
Furthermore, we realized the LLM inference presents two distinct stages: prefill (which is often compute-bound) and decoding (which is often memory-bound). In ThunderServe: High-performance and Cost-efficient LLM Serving in Cloud Environments, MLSys 2025’, we proposed to use different GPUs to serve different stages to utilize heterogeneous GPUs. To achieve this goal, we designed 1) lightweight compression of KV cache to speed up the transmission of intermediate states; 2) lightweight rescheduling to tackle dynamic availability of GPUs.
Scaling
Another question we were often asked is “how many GPUs do we need to support X users”, or “when should I spin up more nodes”? This is often hard to answer as it depends on many factors: how many input tokens vs. output tokens; how many concurrent users; latency and throughput constraints, etc.
The most intuitive way to decide whether to scale out or not is by resource utilization: e.g., if the GPU usage is high, then we scale it out horizontally. However, for LLMs, even a single long input could lead to high GPU utilization. In this case, GPU utilization is not an ideal metric for scaling out.
To better understand this question, we benchmark our system with up to 32 GPUs and 128 concurrent requests, under various settings.
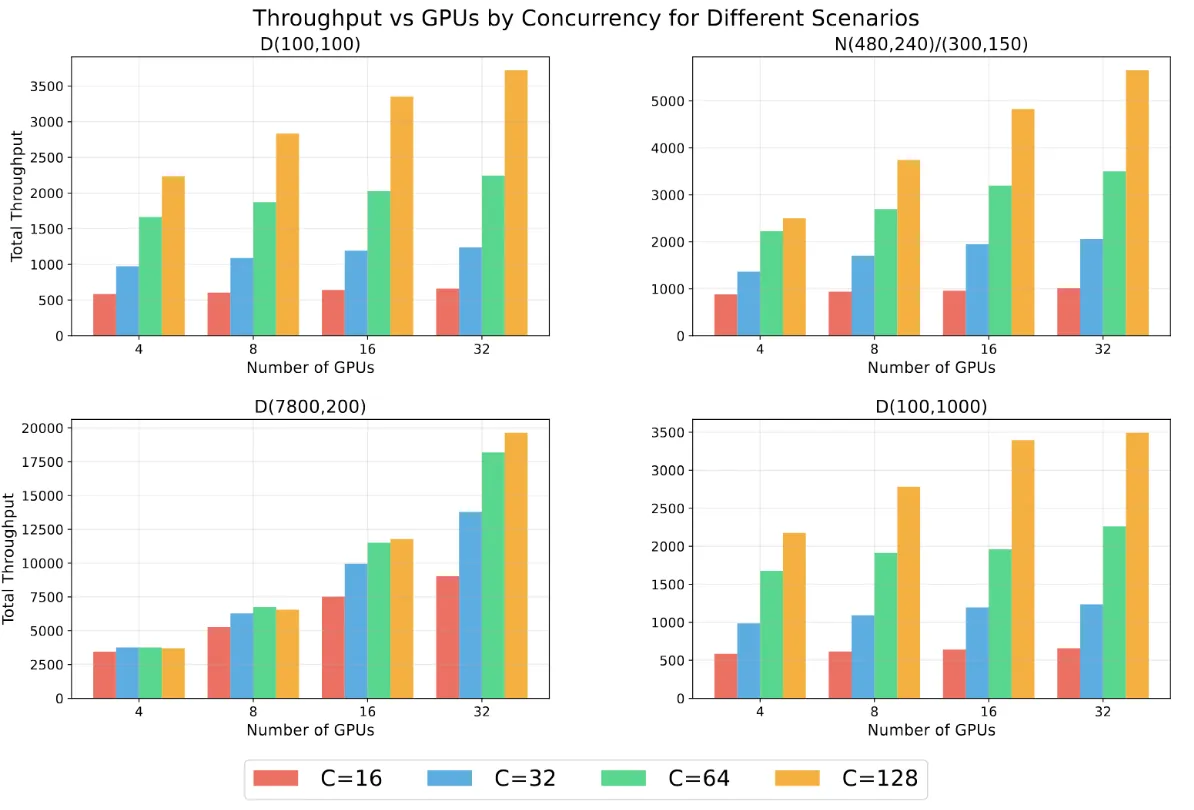 Figure 4: Scaling behavior of Swiss AI Serving system. D(X, Y) means a deterministic number of input tokens X and Y output tokens. N(X, Y)/(P, Q) means a normal distribution of input tokens with the mean X, standard deviation Y, and output tokens with the mean P and standard deviation Q. Different bars represent different numbers of concurrent requests.
Figure 4: Scaling behavior of Swiss AI Serving system. D(X, Y) means a deterministic number of input tokens X and Y output tokens. N(X, Y)/(P, Q) means a normal distribution of input tokens with the mean X, standard deviation Y, and output tokens with the mean P and standard deviation Q. Different bars represent different numbers of concurrent requests.
This shows the scaling behavior of LLM serving systems: with long input prompts, scaling to more nodes effectively improves the throughput by a large margin (as it is more compute-bound); while with long output, scaling to more nodes does not help much.
Energy Consumption
It is a bit hard to give a concrete number, but you might be surprised by how little energy we need to serve the model!
With 4xA100 serving a 70B Llama model at FP16, we are able to produce ~2000 tokens per second with reasonable batch size. As a rough estimation: the energy cap for a single A100 SXM is 400W. Running the service at peak for 1 hour consumes $4 * 400W * 1h=1600Wh$, producing $2000 * 3600=7.2$ million tokens. That means, we generate 4500 tokens per 1Wh energy, or assuming an average 1000 tokens per query, that costs roughly $0.22Wh$. Of course, in reality, if we have lower batch size this may vary, and we will need to add the power consumption for the whole system (CPUs, memory, AC, etc.). In comparison, Google reports $0.24Wh$ of energy consumption for the median Gemini Apps text prompt — which is equivalent to watching ~9 seconds of TV.
We rely a lot on CSCS (the Swiss National Super Computing Center), which is carbon neutral and uses energy from hydropower. For cooling, it uses water from the Lake Lugano and after cooling the water goes back to the lake. CSCS also uses the waste heat from the cooling cycle to heat their building! If you are interested in the energy aspect of CSCS, this document explains it very well.

Acknowledgement
I am very grateful to the people behind this system. Ilia Badanin from EPFL build several tools, notably a tool that helps people to spin up arbitrary models and the main serving website; Elia Palme from CSCS helped iron out several fatal bugs; Alexander Sterfeld from HES-SO helped set up the chat interface and Imanol Schlag from ETH AI Center has been supportive along the way. Of course, it will never be possible without the support from my advisor Ana Klimovic!
Cite this post (BibTeX)
@article{yao2025reflection,
title = {Reflection on Building Swiss AI Serving},
author = {Xiaozhe Yao},
year = {2025},
month = {august},
url = {https://about.yao.sh/posts/swissai-serving/},
note = {Accessed: 2026-03-17}
}