DeltaZip: Serve Multiple Full-Model-Tuned LLMs
DeltaZip is a system for compressing and serving full-parameter fine-tuned LLMs.
Abstract
Fine-tuning large language models (LLMs) greatly improves model quality for downstream tasks. However, serving many fine-tuned LLMs concurrently is challenging due to the sporadic, bursty, and varying request patterns of different LLMs. To bridge this gap, we present DeltaZip, an LLM serving system that efficiently serves multiple full-parameter fine-tuned models concurrently by aggressively compressing model deltas by up to 10x while maintaining high model quality. The key insight behind this design is that fine-tuning results in small-magnitude changes to the pre-trained model. By co-designing the serving system with the compression algorithm, DeltaZip achieves 2x to 12x improvement in throughput compared to the state-of-the-art systems.
Approach
We observe that the weight updates from the pre-trained model to the fine-tuned model are small in magnitude, and smoothly distributed.
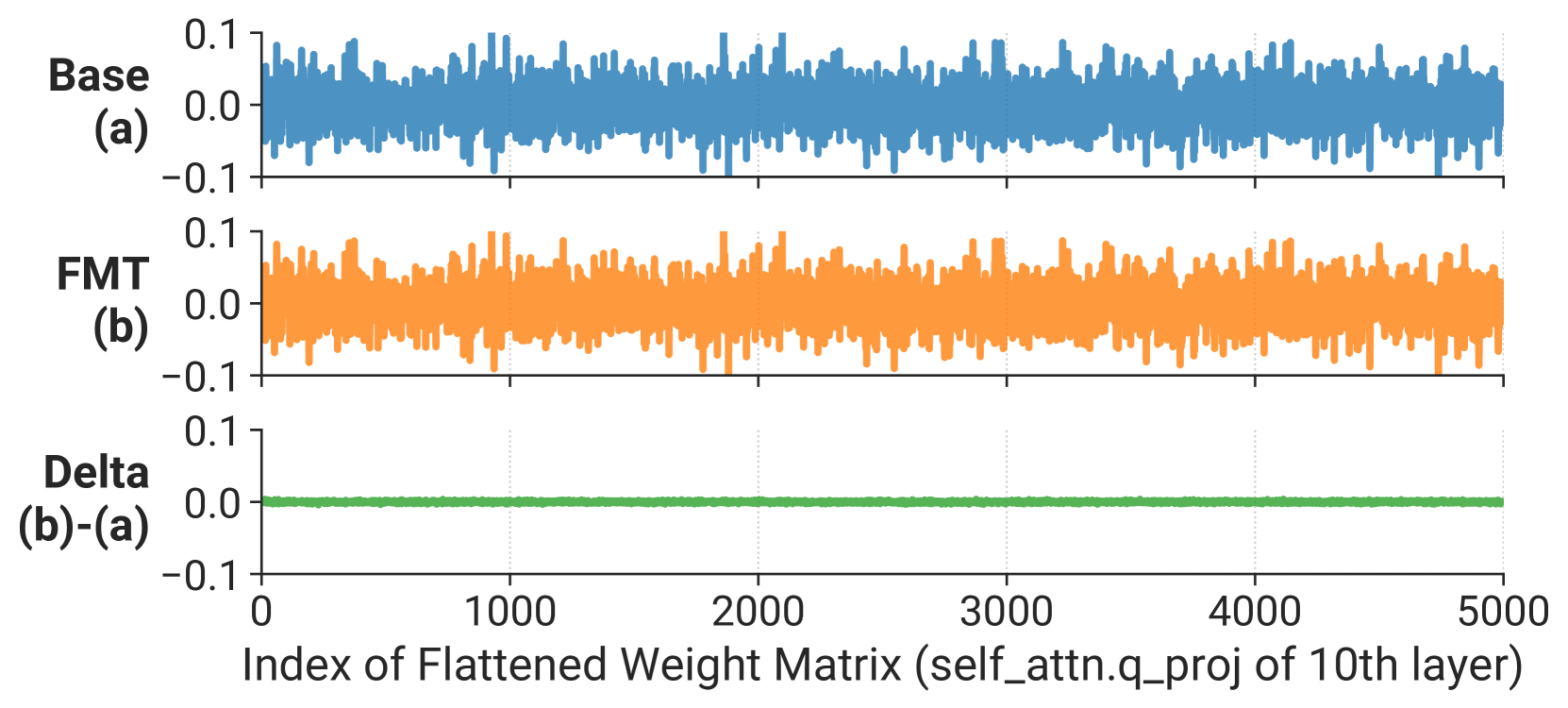
Inspired by this motivation, we compose an aggressive compression pipeline that includes both structured sparsity and quantization. The pipeline consists of the following steps:
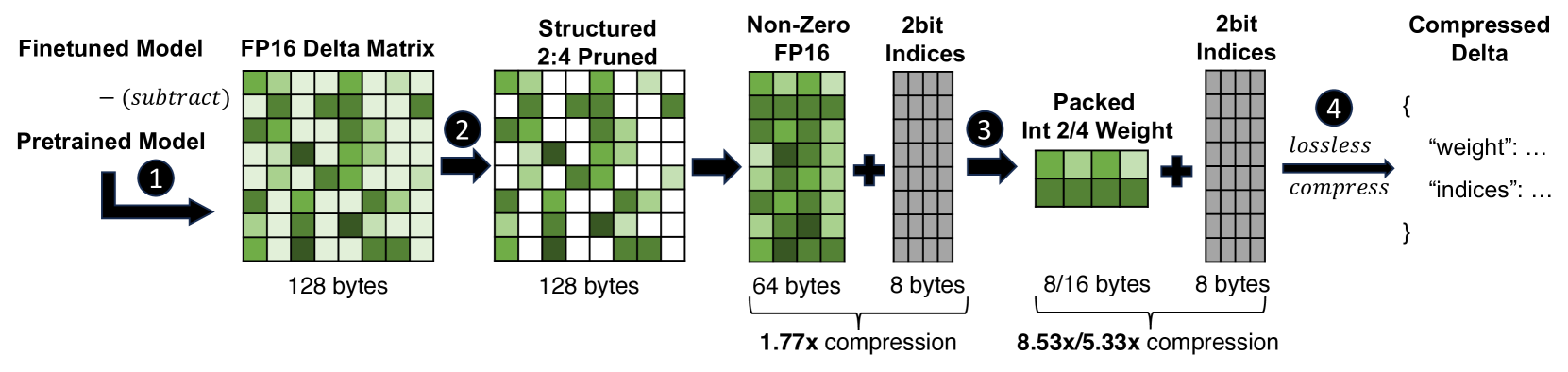
This pipeline is designed to be efficient in both compression ratio and inference speed: 1) We employ structured sparsity, which is supported by recent hardware accelerators, such as post-ampere NVIDIA GPUs. 2) By compression, we reduce the data movement needed from GPU HBM to the compute unit, which is the main bottleneck in LLM inference.
Cite this post (BibTeX)
@article{yao2025deltazip,
title = {DeltaZip: Serve Multiple Full-Model-Tuned LLMs},
author = {Xiaozhe Yao},
year = {2025},
month = {april},
url = {https://about.yao.sh/posts/deltazip/},
note = {Accessed: 2026-03-17}
}